As machine learning is moving towards automated and streamlined tasks and processes, it is crucial to keep track of all the multiple runs, metrics and versions of the models. Version control practices, as commonly used in software development lifecycles, has numerous known benefits.
Why ML versioning is important
- Finding the best model from multiple runs and hyperparameters settings
- Failure tolerance - to revert to working models incase of failure
- Dependency tracking with regards to datasets, frameworks
- Staged deployment for update cycles
- AI /ML governance - control access, implement policy and model maintenance
MLflow
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It has four primary functions namely, MLflow Tracking, MLflow Projects, Mlflow Models and MLflow registry. You can read more about them in their documentation. For versioning, we utilise the MLfow tracking functionality which tracks experiments to record and compare parameters and results
MLflow tracking provides an API and UI for logging parameters, code versions, metrics and output files when running machine learning code.
The following information is recorded for each run; Code version, start & end time, parameters used, model metrics and output artifacts from the model. This tracking can be machine learning library agnostic and runs can be recorded through multiple MLflow APIs- Python, R, Java and REST
The MLFlow runs can be logged to local directory, to a database or a remote tracking server. For a local directory, as shown in figure below; the artifact and backend stores are situated in the ./mlruns folder on the local directory. For remote tracking, cloud provider solutions like AWS S3 and RDS can be used for artifact and backend storage plus AWS SageMaker as the Machine learning workbench.
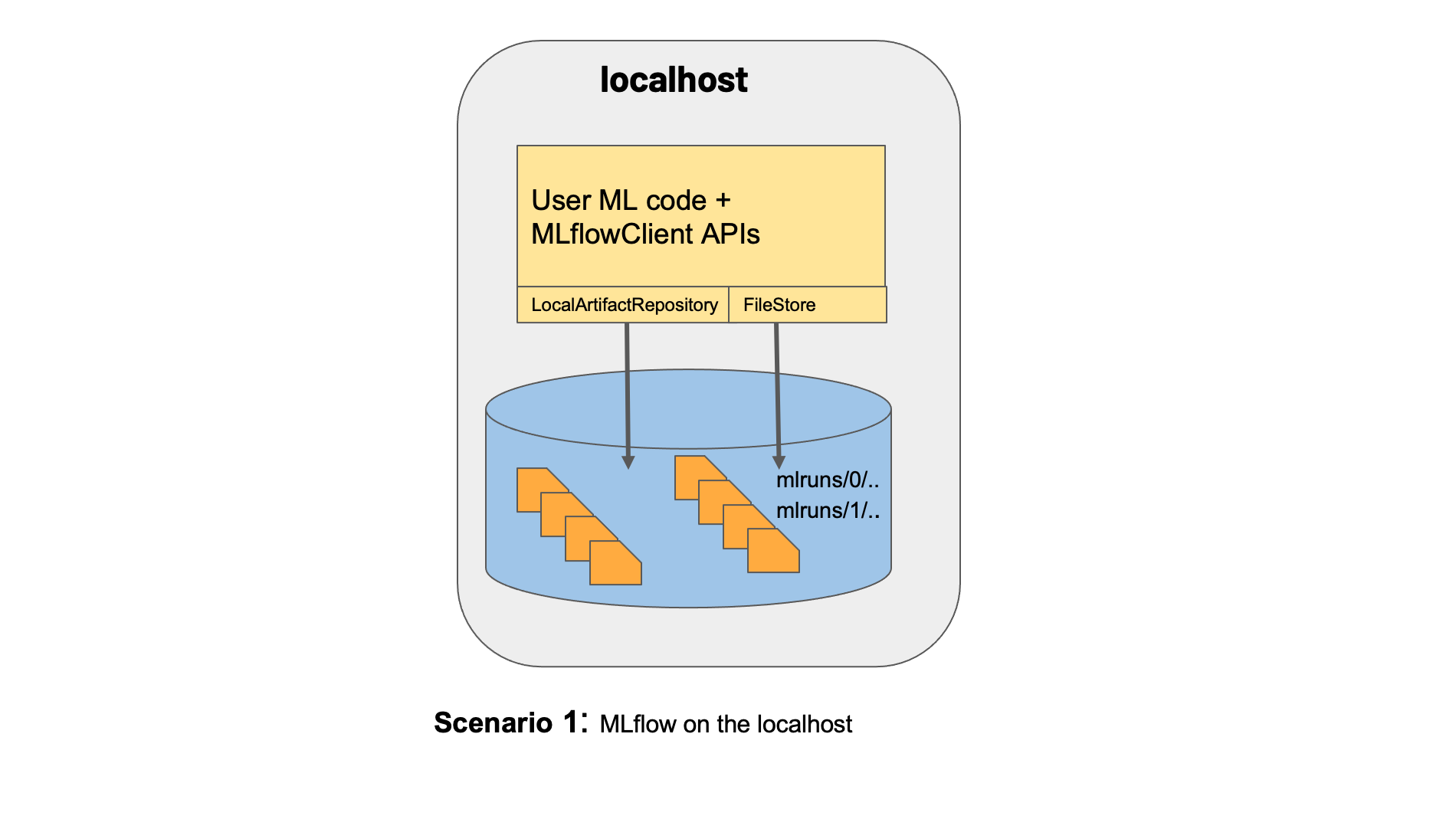
Below is a basic Python example:
pip or conda install sklearn, mlflow and joblib libraries before hand.
#!/usr/bin/python
# -*- coding: utf-8 -*-
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
import mlflow
import mlflow.sklearn
import joblib
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
(X_train, X_test, y_train, y_test) = train_test_split(X, y,
test_size=0.25, random_state=10)
experiment_id = mlflow.set_experiment('MLflow try out')
try:
with mlflow.start_run(experiment_id=experiment_id):
data_scaler = StandardScaler()
data_scaler.fit(X_train)
X_train_std = data_scaler.transform(X_train)
X_test_std = data_scaler.transform(X_test)
# dump sklearn file into a file for easy reloading
scaler_filename = 'scaler.gz'
joblib.dump(data_scaler, scaler_filename)
# log artifact
mlflow.log_artifact(scaler_filename)
# Support Vector Machine SKLearn model
svm = SVC(kernel='rbf', random_state=0, gamma=.10, C=1.0)
svm.fit(X_train_std, y_train)
# log fitted model to mlflow local store
mlflow.sklearn.log_model(svm, 'SVM')
y_predicted = svm.predict(X_test_std)
test_accuracy = accuracy_score(y_test, y_predicted)
# log model metric to mlflow local store
mlflow.log_metric('test_accuracy', test_accuracy)
except e:
raise e
finally:
mlflow.end_run()MLFlow has a wide range of interesting possibilities for versioning and various integrations with popular libraries and cloud providers.
Resources
- For more information, have a look at MLflow documentation
Other ML versioning and lineage tools include:
- Data Version Control(DVC) : Open Source Version Control System for Machine Learning Project
- Pachyderm : Data Lineage with End-to-End Pipelines